Thinking Longer, Not Always Smarter
Evaluating LLM Capabilities in Hierarchical Legal Reasoning
⚡ TL;DR
In U.S. legal practice, case-based reasoning is a cornerstone. As Large Language Models (LLMs) show remarkable capabilities in various reasoning tasks, a critical question emerges: Can they handle the complex, nuanced reasoning required in law?
This work introduces an innovative formal framework that deconstructs finding "significant distinctions" into three tasks of increasing complexity. Through a comprehensive evaluation of modern reasoning LLMs, the research uncovers a striking paradox that thinking longer does not always mean thinking smarter:
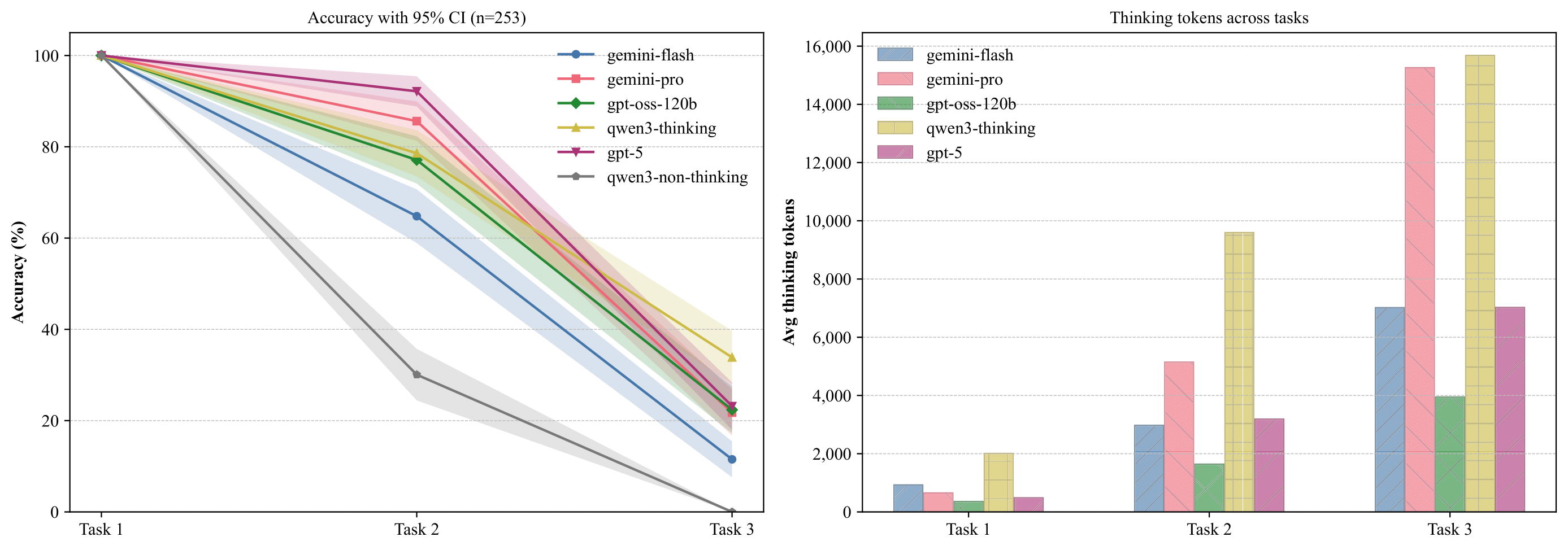
Result A. Model performance across Tasks 1-3. The left panel illustrates accuracy, showing a decline as tasks become more complex. The right panel displays the average number of thinking tokens used, which increases with task difficulty.
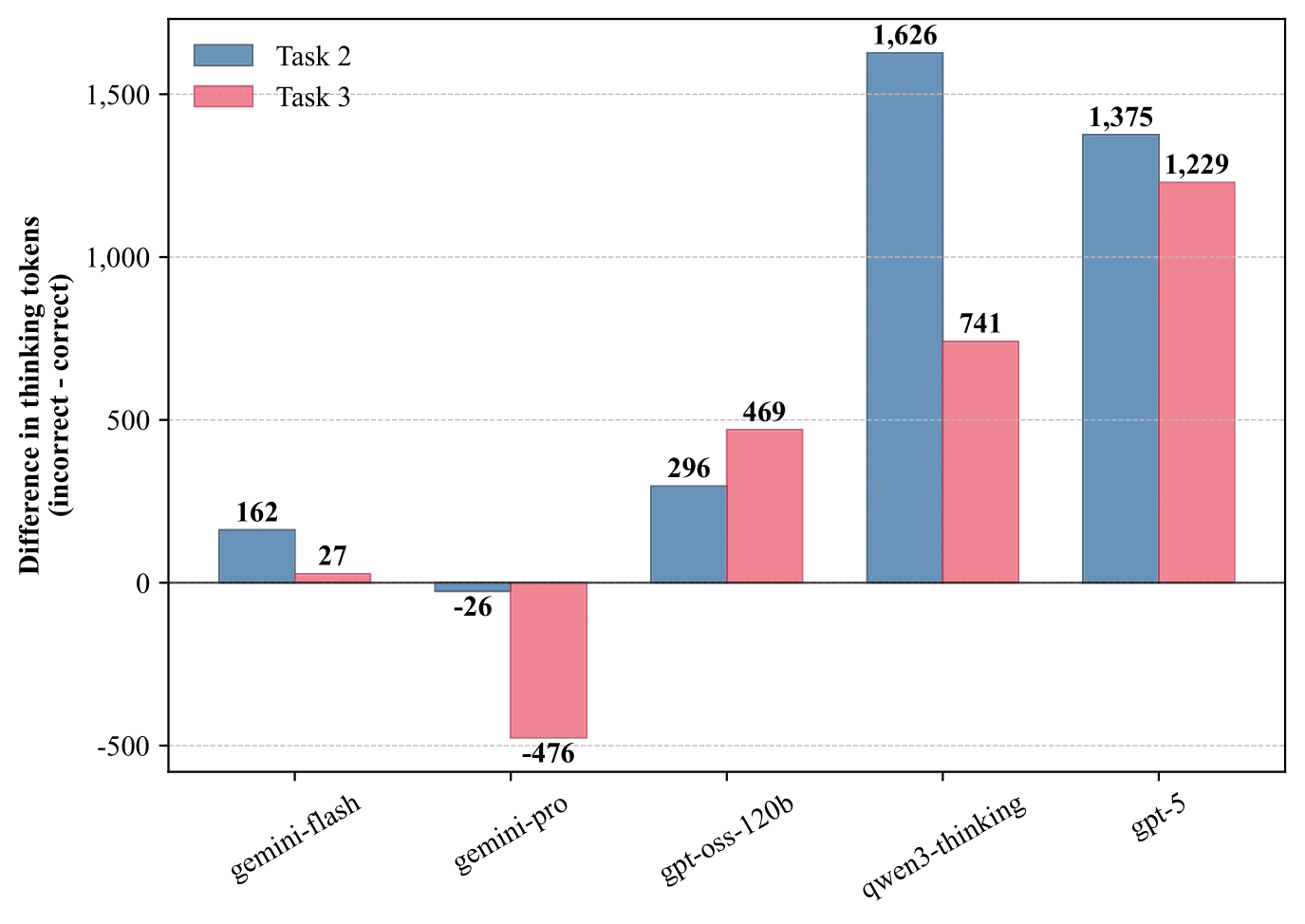
Result B. Token usage patterns reveal inefficient reasoning strategies. The figure shows the difference in thinking tokens between incorrect and correct responses across Tasks 2-3, highlighting how models often expend more computational effort on answers they ultimately get wrong.
⚙️ Experimental Method and Design
Evaluation Pipeline
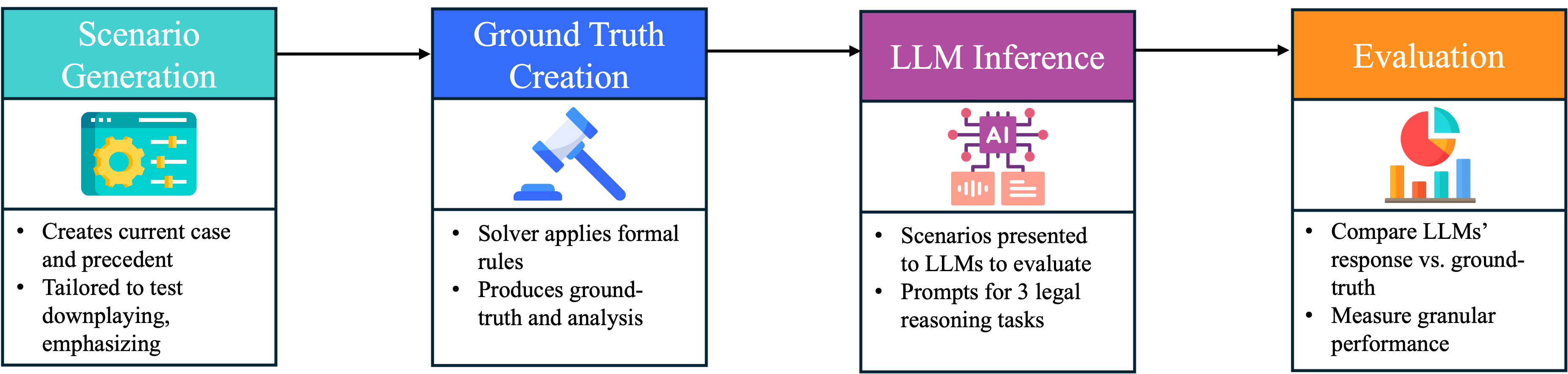
Figure 1. The pipeline consists of four stages: 1) Scenario Generation: Creates pairs of cases tailored to test specific legal reasoning challenges like blocking and downplaying. 2) Ground Truth Creation: A deterministic solver applies the formal rules to produce the correct answer for each task. 3) LLM Inference: The scenarios are presented to LLMs via structured prompts. 4) Evaluation: LLM responses are compared against the ground truth to measure performance.
Experimental Details
- Dataset: 253 test instances per task.
- Knowledge Hierarchy: Provided in Mermaid format.
- Models: gpt-5, qwen3-thinking, gpt-oss-120b, gemini-pro, gemini-flash; control: qwen3-non-thinking.
- Params: temperature=0.3, top_p=0.95, max_tokens=65536.
🧩 A Decomposed Framework for Identifying Significant Distinctions
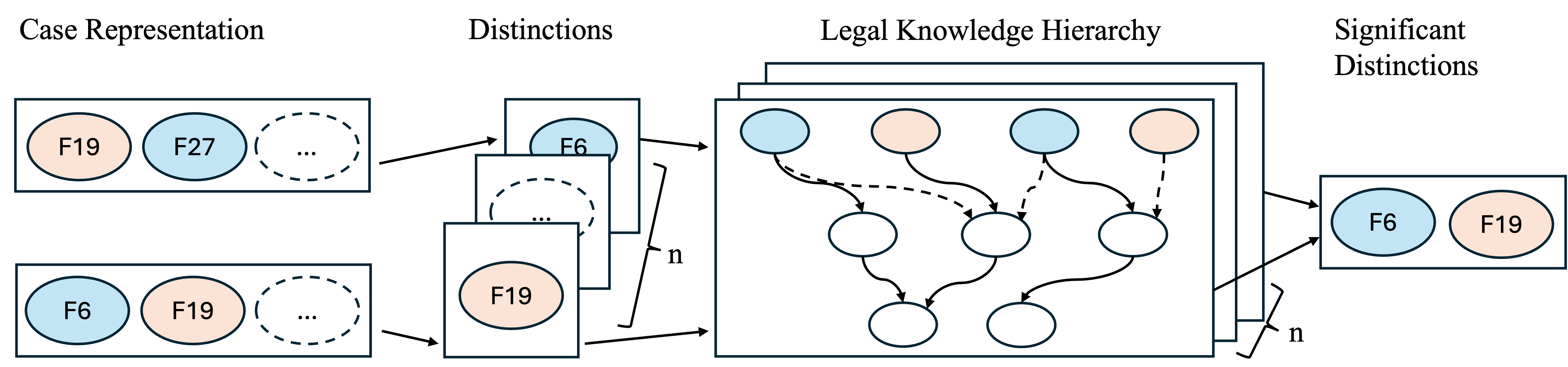
Figure 2. The decomposed framework for identifying significant distinctions, which consists of three steps: (1) identify distinctions, (2) analyze argumentative roles of a distinction via legal knowledge hierarchy, and (3) identify significant distinctions. Red and blue presents the favoring side of the factors.
Case Representation
- Definition 1: Factor
- A legal case can be distilled into a set of legally relevant, stereotyped fact patterns called "factors". A factor f is a predicate representing such a fact. The set of all possible factors is denoted by 𝔉. Each factor f ∈ 𝔉 has a favored party, s(f) ∈ {p, d}, where p is the plaintiff and d is the defendant.
- Definition 2: Case
- A case C is represented as a pair (F, o), where F ⊆ 𝔉 is the set of factors present in the case, and o ∈ {p, d} is the outcome (the winning party). In the analysis, we consider a current case C1 = (F1, o1) and a precedent case C2 = (F2, o2).
Hierarchy of Legal Knowledge
- Definition 3: Hierarchy and Nodes
-
The legal knowledge hierarchy is a DAG G = (V, E), where:
- The set of nodes V = 𝓕 ∪ 𝓒 ∪ 𝓘 comprises base-level factors (𝓕), intermediate legal concerns (𝓒), and top-level legal issues (𝓘).
- The set of edges E represents support relationships. An edge from node u to v means u provides evidence for v.
- Definition 4: Edge Strength
- Each edge e ∈ E has a strength, σ(e) ∈ {strong, weak}.
Framework for Identifying Significant Distinctions
Task 1: Identify Distinctions
This foundational step involves finding all factual differences that could make the precedent a poor analogy.
- Definition 5: Distinction
-
Given a current case C1=(F1, o1) and a precedent C2=(F2, o2), a factor f is a "distinction" if it satisfies one of the following conditions:
- Type 1: The factor is a strength for the precedent's winner that the current case lacks: f ∈ F2 ∧ f ∉ F1 ∧ s(f) = o2.
- Type 2: The factor is a weakness for the precedent's loser that is present in the current case: f ∈ F1 ∧ f ∉ F2 ∧ s(f) ≠ o2.
Task 2: Analyze Argumentative Roles of A Distinction
Whether a distinction is persuasive depends on its role in the knowledge hierarchy. This step requires deeper, hierarchical reasoning.
- Definitions 6-8: Effective Support & Blocking
- A path π(f, P) from a factor f to an ancestor concern P can be strong or weak. If a factor supports P via a weak path, but an opposing factor in the same case supports P via a strong path, the former's support is "blocked". A factor provides "effective support" for P if its path is strong, or if it is weak and not blocked.
- Definitions 9 & 10: Downplaying & Emphasizing
-
- A distinction D can be emphasized if it provides effective support for a concern P for which the other case lacks any effective support. This creates a crucial argumentative gap.
- A distinction D can be downplayed if, in the other case, an alternative factor f_alt exists that provides effective support for the same concern P. This points to other facts that serve the same argumentative purpose.
Task 3: Identify All Significant Distinctions
This is the final, integrative task that synthesizes all previous analyses.
- Definition 11: Significant Distinction
- A significant distinction represents a fundamental difference between cases that provides a strong basis for arguing for a different outcome: A distinction D is "significant" if and only if it can be emphasized and it cannot be downplayed.
📋 An Illustrative Example of the Decomposed Framework
To illustrate our three-task framework, we use an example from U.S. trade secret law to walk through each task. For example, we can consider the following cases:
- Current Case (C1): Company A (plaintiff) is suing a former employee (defendant) for trade secret theft. The employee knew the information was confidential. Company A lacked security measures, and they waived their employees' confidentiality agreement.
- Precedent Case (C2): Company B (plaintiff) lost a trade secret lawsuit against a former employee (defendant) because they lacked security measures.
Factor Representation
The natural language narratives can be translated into a set of pre-defined factors. A (d) marks a factor favoring the defendant, while (p) favors the plaintiff. For instance, "lacked security measures" corresponds to F19_No-Security-Measures(d), which hurts the plaintiff's claim. Conversely, the employee knowing the information was confidential (F21_Knew-Info-Confidential(p)) supports the plaintiff's argument, but waiving confidentiality agreement (F23_Waiver-of-Confidentiality(d)) weakens their claim. The factor representations for our example cases are as follows:
- Current Case (C1) Factors: F19_No-Security-Measures(d), F21_Knew-Info-Confidential(p), F23_Waiver-of-Confidentiality(d)
- Precedent Case (C2) Factors: F19_No-Security-Measures(d)
- Precedent (C2) Winner: Defendant
Task 1: Identify Distinctions
With the cases represented as factors, the first task is to identify all unshared factors that could serve as distinctions.
A distinction is an unshared factor that indicates the precedent case (C2) is not a good analogy for the current case (C1). There are two types of distinctions:
- A factor favoring C2's winner is present in C2 but absent in C1.
- A factor favoring C2's loser is present in C1 but absent in C2.
For our example:
- Question 1.1: Are there any pro-defendant factors from C2 (the winner) that are absent in C1? C2 has F19_No-Security-Measures(d) which favors the defendant. C1 also has F19_No-Security-Measures(d). Therefore, there are no distinctions from this condition.
- Question 1.2: Are there any pro-plaintiff factors in C1 (favoring C2's loser) that were not in C2? Yes. C1 has F21_Knew-Info-Confidential(p) which favors the plaintiff. C2 does not have this factor. Therefore, F21(p) is a distinction.
Conclusion for Task 1: The identified distinction is F21(p).
Tasks 2 & 3: Analyze and Identify Significant Distinctions
The next steps involve using a legal knowledge hierarchy to determine which distinctions are significant.
The Factor Hierarchy
Factors provide evidence for more abstract legal concerns, which in turn inform high-level legal issues. In our example, we have two legal issues:
- Legal Issue I101: Did the plaintiff's information constitute a trade secret?
- Concern C102: Did the plaintiff take efforts to maintain secrecy? This concern is supported or weakened by F23_Waiver-of-Confidentiality(d) and F19_No-Security-Measures(d).
- Legal Issue I114: Was there a confidential relationship?
- Concern C115: Did the defendant have notice of confidentiality? This concern is supported by F21_Knew-Info-Confidential(p).
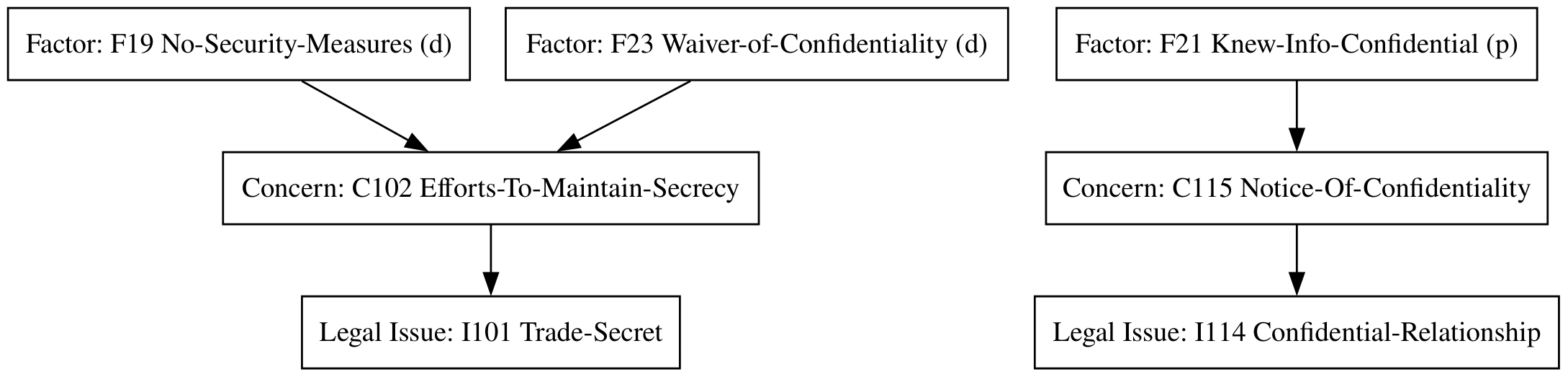
Figure 3. An example factor hierarchy for trade secret law, connecting base-level factors to intermediate legal concerns and top-level legal issues. Solid lines indicate strong support and dashed lines indicate weak support; this support can be for or against a concern, depending on which party the factor favors.
Emphasis, Downplay, and Significance
The significance of a distinction depends on whether it can be emphasized or downplayed. A distinction is significant if it can be emphasized and cannot be downplayed.
Definition of Downplaying: A distinction D can be downplayed if you can find an ancestor concern P that meets both conditions: (1) P is an ancestor of D in the hierarchy, and (2) In C1, a different factor (F_{\text{alt}}) provides support for that same concern P.
Definition of Emphasizing: A distinction D can be emphasized if you can find an ancestor concern P that meets both conditions: (1) P is an ancestor of D, and (2) The precedent case C2 lacks any factor that provides support for P (when the distinction favors C2's loser) OR the current case C1 lacks any factor that provides support for P (when the distinction favors C2's winner).
- Analysis of F21(p): F21(p) supports C115 (Notice-Of-Confidentiality), which supports I114 (Confidential-Relationship). Since F21(p) favors C2's loser (plaintiff), we check if C2 lacks any factor providing support for C115. The Precedent Case (C2) has no pro-plaintiff factor supporting this concern. The absence of F21(p) in C2 is critical because it leaves this point entirely unsupported for the plaintiff in C2. Therefore, F21(p) can be emphasized. For downplaying, C1 has F21(p) as the only pro-plaintiff factor providing support for C115. While C1 also has F23_Waiver-of-Confidentiality(d) and F19_No-Security-Measures(d), these factors favor the defendant, not the plaintiff. Therefore, there is no alternative pro-plaintiff factor that can downplay the distinction. Thus, F21(p) cannot be downplayed. Table 1 summarizes the significance analysis for this distinction.
Defendant's Counsel in C1 would need to counter-argue: To downplay this distinction, the defendant would need to show that the underlying concern C115 (Notice-Of-Confidentiality) is still addressed by alternative factors in C1. However, F21(p) is the only pro-plaintiff factor providing support for C115 in C1. While C1 has F23_Waiver-of-Confidentiality(d) and F19_No-Security-Measures(d), these factors favor the defendant, not the plaintiff. Therefore, there is no alternative pro-plaintiff factor that can downplay the distinction, leaving it successfully emphasized by the plaintiff.
| Distinction | Can be Emphasized? | Can be Downplayed? | Significant? |
|---|---|---|---|
| F21(p) | YES | NO | YES |
Conclusion for Task 3: The significant distinction is F21(p). The existence of this significant distinction suggests the precedent C2 should not apply in the current case C1.
📊 Experimental Results & Core Conclusions
The experimental results clearly reveal systemic weaknesses in how current reasoning LLMs handle hierarchical legal reasoning tasks.
Figure 4. Model performance across Tasks 1-3. The left panel illustrates accuracy, showing a decline as tasks become more complex. The right panel displays the average number of thinking tokens used, which increases with task difficulty.
Finding 1: Performance Degrades Sharply with Task Complexity
- Task 1 (Surface-level Identification): All models achieve 100% accuracy, indicating they excel at simple pattern recognition and comparison.
- Task 2 (Hierarchical Reasoning): Accuracy drops significantly, ranging from 64.82% (gemini-flash) to 92.09% (gpt-5).
- Task 3 (Integrated Analysis): Performance collapses, with accuracy plummeting to a range of 11.46% (gemini-flash) to 33.99% (qwen3-thinking), showing that integrating multiple reasoning steps is a major challenge.
| Model | Accuracy (%) | Thinking Tokens | ||||
|---|---|---|---|---|---|---|
| Task 1 | Task 2 | Task 3 | Task 1 | Task 2 | Task 3 | |
| gemini-flash | 100.00 | 64.82 | 11.46 | 654.90 | 5,144.72 | 15,262.17 |
| gemini-pro | 100.00 | 85.77 | 21.74 | 929.30 | 2,973.59 | 7,019.41 |
| gpt-oss-120b | 100.00 | 77.08 | 22.53 | 356.56 | 1,642.34 | 3,942.67 |
| qwen3-thinking | 100.00 | 78.66 | 33.99 | 2,010.80 | 9,596.17 | 15,677.82 |
| gpt-5 | 100.00 | 92.09 | 23.32 | 487.01 | 3,189.27 | 7,025.01 |
| qwen3-non-thinking | 100.00 | 30.04 | 0.00 | / | / | / |
Finding 2: The "Thinking Longer, Not Smarter" Paradox
This is the most surprising finding: models consistently expend more computational resources (thinking tokens) on answers they get wrong.
Figure 5. Token usage patterns reveal inefficient reasoning strategies. The figure shows the difference in thinking tokens between incorrect and correct responses across Tasks 2-3, highlighting how models often expend more computational effort on answers they ultimately get wrong.
For instance, in Task 2, gpt-5 used an average of 4,456 tokens for incorrect responses compared to 3,081 for correct ones—a 45% increase in computational effort for a worse outcome. This suggests that when models encounter difficult problems, they may fall into inefficient reasoning loops or engage in extensive but unfocused analysis rather than effectively finding the correct path.
| Model | Task 2 | Task 3 | ||
|---|---|---|---|---|
| Correct | Incorrect | Correct | Incorrect | |
| gemini-flash | 5,087.61 | 5,249.65 | 15,263.26 | 15,290.12 |
| gemini-pro | 2,977.37 | 2,951.14 | 7,371.33 | 6,895.77 |
| gpt-oss-120b | 1,568.21 | 1,864.57 | 3,607.08 | 4,076.53 |
| qwen3-thinking | 9,246.05 | 10,872.13 | 15,392.91 | 16,133.68 |
| gpt-5 | 3,081.44 | 4,456.33 | 6,126.01 | 7,354.63 |
Finding 3: No Strong Correlation Between Effort and Performance
- High Cost ≠ High Performance:
qwen3-thinkingused the most tokens in all tasks but did not achieve the highest accuracy in Task 2. Specifically, it used 3.0 times more tokens thangpt-5in Task 2 for worse performance. - The Efficiency of Quality Reasoning:
gpt-5demonstrated the most efficient reasoning in the study, achieving high accuracy with moderate token usage. This finding challenges the assumption that more reasoning effort leads to better outcomes; instead, the quality of reasoning is more important than the quantity.
Finding 4: The Value of Intermediate Reasoning
By comparing qwen3-thinking to its non-thinking counterpart, the study demonstrates the performance gain from intermediate reasoning processes.
- In Task 2, the thinking model's accuracy (78.66%) was a 2.6-fold improvement over the non-thinking model (30.04%).
- In Task 3, the non-thinking model failed completely (0.00% accuracy), while the thinking model maintained some capability (33.99%).
This confirms that reasoning capabilities enabled by post-training strategies are beneficial for hierarchical reasoning tasks, though their effectiveness diminishes on the most complex, integrative tasks.
💡 Case Study
To provide a qualitative understanding of the models' reasoning processes, we analyze excerpts from the thinking traces of qwen3-thinking and gpt-oss-120b on one instance of Task 3. This analysis reveals stark differences in reasoning styles and efficiency.
qwen3-thinking: A Verbose and Repetitive Process
The reasoning trace for qwen3-thinking is characterized by its verbosity and a tendency to repeatedly re-state definitions and the primary goal. The trace begins with a lengthy preamble where the model outlines the task and defines the core concepts multiple times before processing the input.
First, I need to identify all significant distinctions between the current case (C1) and the precedent case (C2). [...] The key definitions:
- A distinction is an unshared factor between C1 and C2. There are two types:
- A factor favoring C2's winner (defendant) is present in C2 but absent in C1.
- A factor favoring C2's loser (plaintiff) is present in C1 but absent in C2.
[...] So we have four distinctions: F11(d), F27(d), F15(p), F18(p). Now, for each of these, I need to check if it is significant. A significant distinction: can be emphasized and cannot be downplayed. [...] Let me read carefully. "A distinction can be emphasized if..." "A distinction can be downplayed if..." [...]
When analyzing specific distinctions, the model proceeds with a step-by-step application of the rules. However, this process is again marked by verbosity. The excerpt below shows the model correctly concluding that distinction F27(d) is not significant because it can be downplayed, but the reasoning is exhaustive.
[...] Now, for downplay: a distinction can be downplayed if there is a concern/issue where F27 has support for defendant and C1 has alternative effective support for defendant. For C102: F27 has support for defendant, and C1 also has support for defendant (from F1 via C122), so for C102, C1 has alternative support for defendant. [...] So for C102, downplay is possible. [...] Therefore, for F27(d), it can be emphasized [...] but it can be downplayed [...], so not significant. [...]
This trace illustrates an inefficient reasoning style while ultimately capable of reaching the correct conclusions for intermediate steps. The model's tendency to "think out loud" about every detail, including redundant definitions, contributes to its high token consumption.
gpt-oss-120b: A More Concise, but Flawed, Approach
In contrast, the reasoning trace for gpt-oss-120b is more concise. The model quickly identifies the distinctions and proceeds to evaluate them without the extensive preamble observed in qwen3-thinking.
[...] C2 winner is defendant. So "favoring C2's winner" = factors that favor defendant (d) present in C2 but not in C1. [...] distinctions: F11(d), F27(d) (type 1). Next plaintiff factors present in C1 but not in C2. [...] distinct plaintiff factors: F15(p), F18(p). Those are type 2 distinctions. Thus total distinctions: F11(d), F27(d), F15(p), F18(p). [...]
However, the model's haste appears to cause a factual error. It fails to identify a key support path in the hierarchy for one of the concerns, leading it to an incorrect conclusion.
[...] Distinction D: F18(p) – effective support for I112 and I110. Check C2 effective support for I112? C2 factors: none linking to I112. [...] So C2 lacks support for I112. Also for I110 (downstream via I112). C2 lacks support. Any alternative support for I112 or I110 from C2? No. So no downplay. Thus F18(p) seems emphasized [...] and not downplayed. So it's significant. [...]
The model missed that in C2, factor F22(p) provides strong support for I110 via concern C111. This oversight led it to incorrectly identify F18(p) as significant. This comparison reveals a trade-off: qwen3-thinking's verbose process, while inefficient, was more methodical and led to a more accurate application of the rules. In contrast, gpt-oss-120b's faster, more direct approach was brittle and resulted in reasoning failures. This suggests that for complex, rule-based reasoning, a more deliberative process may be necessary to ensure accuracy.
📚 Citation
If you find this work useful, please cite our paper:
@article{zhang2025thinking,
title={Thinking Longer, Not Always Smarter: Evaluating LLM Capabilities in Hierarchical Legal Reasoning},
author={Zhang, Li and Grabmair, Matthias and Gray, Morgan and Ashley, Kevin},
journal={arXiv preprint arXiv:2510.08710},
year={2025}
}
Plaintiff's Counsel in C1 argues: "Your Honor, the precedent case C2 is not a good analogy for our current case. In C2, the plaintiff had no factors to support the concern of notice of confidentiality (C115), which supports the legal issue of confidential relationship (I114). However, in our current case C1, we have F21_Knew-Info-Confidential(p), which provides crucial support for C115. The presence of F21(p) in C1 strengthens our position regarding notice of confidentiality, making our case significantly stronger than the plaintiff's position was in C2. This distinction is critical and cannot be dismissed."